Introduction
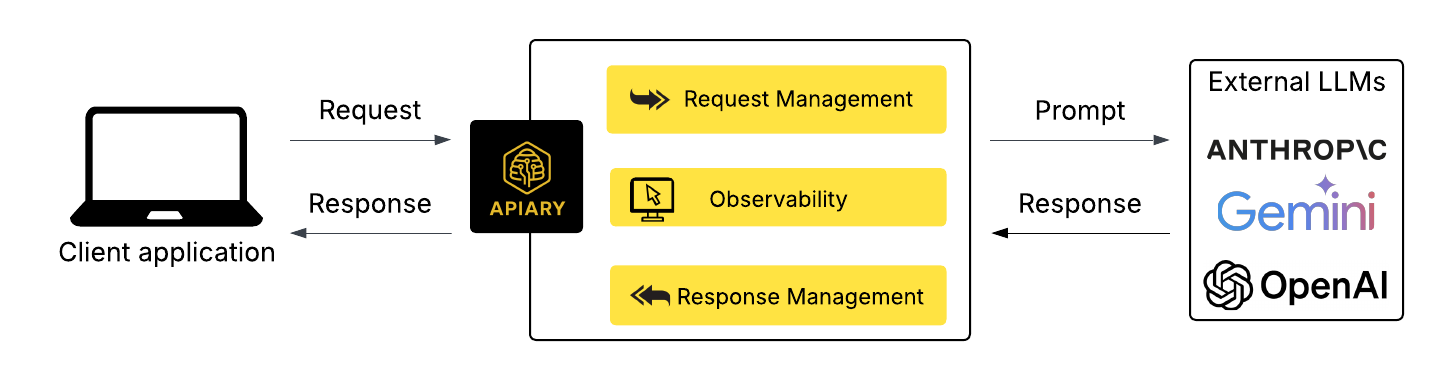
What is Apiary?
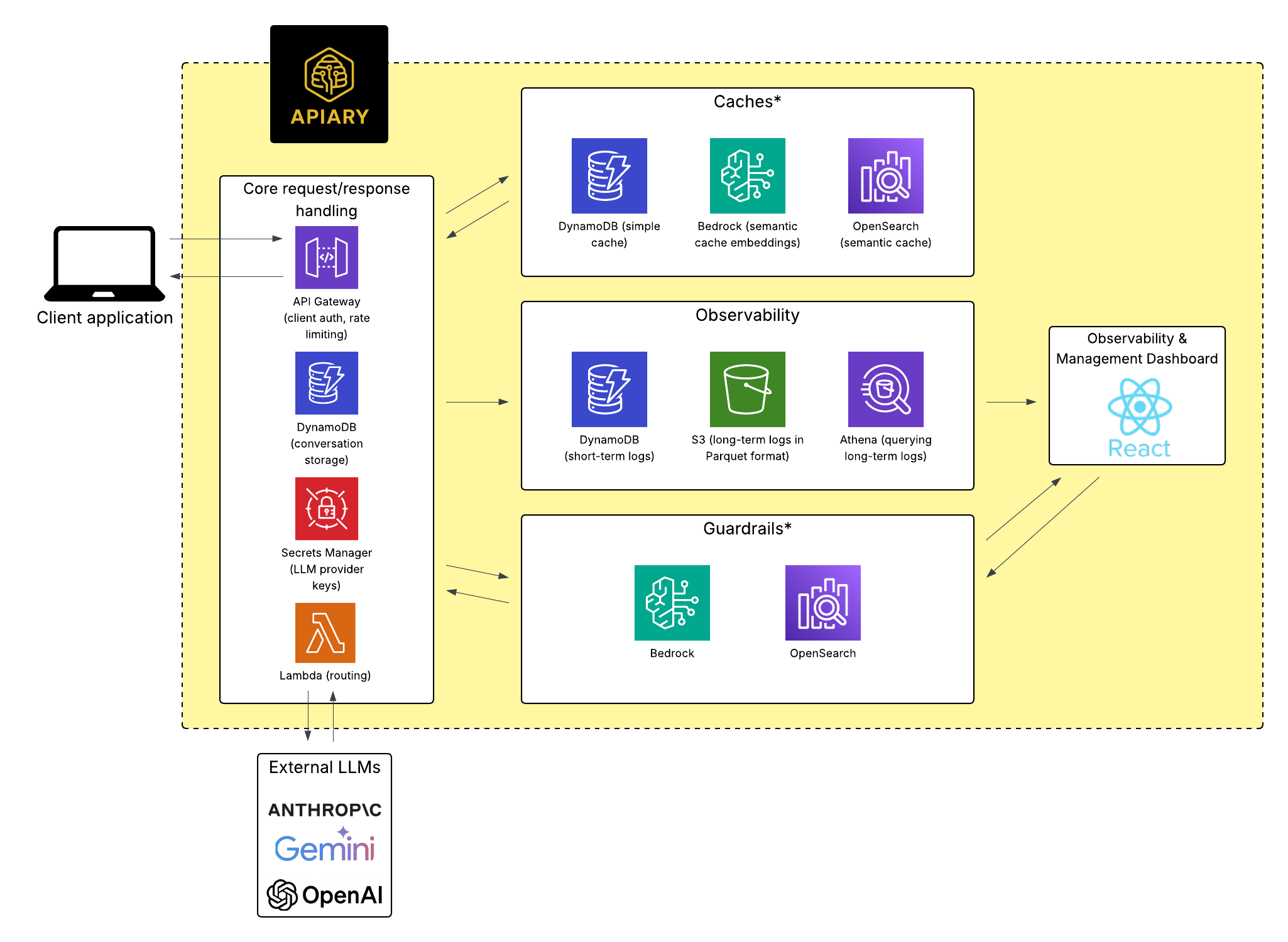
Apiary is an open-source platform for managing requests to one or more large language models (LLMs) via a single API endpoint. Under the hood it can route requests to different LLMs, cache and reuse results, and apply “guardrails” to model outputs. Additionally, it provides observability for every LLM call, allowing developers to view all of their applications’ LLM requests, responses, and costs in one central location.
Developers can experiment and take advantage of the strengths of different models for different use cases within their applications, without having to manage multiple API formats or duplicate infrastructure for shared concerns like routing or guardrails.
Background
Before further exploring the services that Apiary provides, it may be helpful to have more background on how LLMs may be used in applications and the challenges that can arise when integrating one or more LLMs.
Foundation Models and Model-as-a-Service
A foundation model, such as OpenAI's GPT-4, Anthropic's Claude, and Google's Gemini, is a general purpose AI model trained on large amounts of data and exposed via an API, enabling developers to integrate advanced AI capabilities into their applications.Typically, access to these models is provided via API calls to commercial Model-as-a-Service (MaaS) offerings.
Foundation models are used for a wide variety of AI features in applications. Some common examples include:
- Retrieval-Augmented Generation (RAG) and custom chatbots
- Summarization of content such as documents, customer reviews, or academic papers
- Text generation, including product descriptions and blog posts
- Semantic search, using embeddings to retrieve and rank relevant documents
- Visual comprehension, such as image generation and identification
- Multi-modal systems, which are a combination of the above capabilities
It's not uncommon for a single application to employ several of these use cases. Even the simplest AI application often involves multiple LLM calls - it may employ an LLM for classification of a query, as well as an embedding model to retrieve relevant documents, plus an LLM for the response generation, and finally a model for response evaluation. Integrating even one of these LLMs comes with complexity, which we'll discuss next.
Challenges of Working with LLMs
Working with LLMs has its own unique challenges:
- Cost: API calls to LLMs can be expensive, especially for high-usage applications or lengthy queries.
- High Latency: LLMs are typically slower than traditional services, particularly with large prompts or responses.
- Unpredictability: LLMs are inherently non-deterministic and have the potential to generate undesirable responses, possibly exposing sensitive data, hallucinating information, or providing malicious content.
- Availability: Leading models frequently experience downtime or degraded performance, often below the industry standard for high-availability systems.
- Context Management: For chat applications, maintaining state and message history across requests adds a layer of complexity.
As we discussed, even a simple AI application may have a need for using multiple LLMs. Before we get into the challenges of integrating more than one LLM into an application, we'll elaborate on some additional scenarios where more than one LLM may be necessary.
Why Use Multiple LLMs?
Performance and Cost Optimization
LLMs vary widely in price, performance, and behavior. A developer might route high-priority or complex tasks to a more powerful (and more expensive) model, while using smaller, open-source models for simpler or lower-stakes queries.
For instance, Anthropic's Claude might be used for its natural, human-like writing style, while an open-source model may suffice for straightforward classification tasks. A chatbot for a car dealership might use a cheap, fast model to answer "What are your weekend hours?" and a more advanced model for "What would my monthly payment be if I finance this car over 4 years with $4,500 down?"
Reliability and Fallbacks
LLMs often fall short of enterprise reliability standards (e.g., "five nines" or 99.999% uptime). OpenAI and Anthropic models, for example, typically offer only 99.2–99.7% availability 1, 2. In high-availability applications, developers must implement fallback strategies using alternative models to ensure uninterrupted service.
Performance Evaluation and Testing
During development or experimentation, teams often compare responses from different models to determine which performs best. In production, multiple models may be used simultaneously in A/B tests or canary deployments to evaluate response quality, bias, or relevance.
"LLM as a judge", where a separate model evaluates the performance of a primary model, has also emerged as a highly popular way to evaluate LLM responses 3.
Data Sensitivity and Internal Processing
Some organizations, especially in regulated industries, need to handle sensitive data internally. This may mean routing certain queries through self-hosted or internal models before allowing access to external APIs.
Challenges of Using Multiple LLMs
While using multiple models can offer major benefits, it also significantly increases complexity. Developers must contend with:
- Divergent request/response formats: Each provider has a unique API structure, which may change frequently. Even structured responses (e.g., JSON) can vary, requiring extra logic to parse and normalize them.
- Different methods for handling context: Thread management and chat history differ between providers (e.g., OpenAI uses role-based message arrays, while Anthropic requires a system message per request).
- Multiple API keys and credential management: Each model requires its own authentication and security setup.
- Disparate observability systems: Without standardization, tracking cost, token usage, and response quality must be implemented separately for each provider.
- Fallbacks and routing logic: Implementing conditional logic (e.g., routing based on cost, model failure, or task complexity) is error-prone and often duplicated.
Finally, and perhaps most importantly, AI is a rapidly evolving field. Each of the above pain points is amplified by the fact that as API behavior, model availability, and pricing structures change, developers are forced to update the same logic all over the codebase. The sprawl becomes a constant, unmanageable burden.
A New Layer of Abstraction
These challenges aren't going away. If anything, they're growing as LLMs are integrated into more and more applications. Rather than continuing to patch and duplicate logic across every integration, developers need a centralized layer to manage and abstract LLM interactions. This is where a model gateway comes in - a centralized layer that abstracts away the mess of LLM-integrated development.
A model gateway acts as an intermediary between your application and one or more foundation model APIs. It centralizes key responsibilities: routing requests, standardizing request and response formats, managing credentials, tracking usage and cost, and applying operational logic such as retries, caching, and guardrails. To illustrate, the image below shows the user dashboard from an existing model gateway solution, Cloudflare AI Gateway. Each LLM request is routed through the gateway, where it can be tracked and modified according to configured rules.
Existing Solutions
Several tools and platforms have emerged to serve as model gateways. We explored many of these tools in building our product. Each has tradeoffs, which helped us in clarifying what we wanted Apiary to become.
Open Source Tools
- LiteLLM and Portkey (Open Source) are two open source tools that provide unified APIs for calling multiple LLM providers. Each handles request/response formatting and supports basic routing logic. However, they do not offer infrastructure, observability tools, or advanced features like semantic caching or guardrails.
Managed Services
- Cloudflare AI Gateway is a hosted gateway that provides a universal endpoint for LLM requests, basic caching, tracks token usage, and includes analytics. It runs entirely within Cloudflare’s infrastructure.
- Gloo AI Gateway offers a managed control panel for LLM requests with support for routing, observability, rate limiting, and basic content filters. It is built for production-grade deployments and runs on third-party infrastructure.
Tradeoffs
- The open source tools are lightweight and easy to integrate, but they lack infrastructure, observability, and have very limited feature sets.
- Both managed services, Cloudflare AI Gateway and Gloo AI Gateway, are fully managed and easier to use, but you have to give up data control and customization.
Our ideal model gateway would be free to use, offer complete control over our data, provide configurable routing, request and response standardization, cost monitoring, semantic caching, guardrails, and observability. It also needed to be easy to deploy and fully configurable. With this clarity, we set out to build Apiary.
Our Solution
Apiary is a comprehensive, self-managed solution with built-in infrastructure. It's easy to deploy, and gives developers complete control over their data and infrastructure.
How Apiary Compares to Alternatives
In the table below, we've selected one open-source tool (Portkey) and one hosted solution (Cloudflare AI Gateway) to compare alongside Apiary.
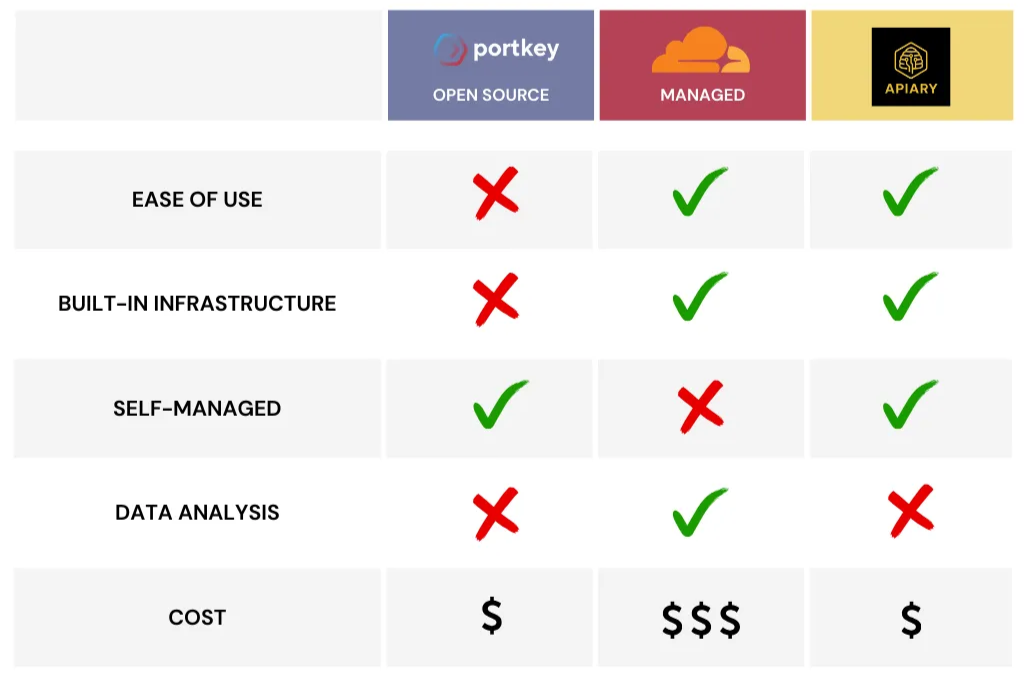
As the chart illustrates, Apiary combines the strengths of both open-source flexibility and managed service convenience.
Apiary differentiates itself from existing solutions through a unique combination of features:
- Complete Data Control
Unlike managed services like Cloudflare AI Gateway, Apiary runs entirely within your own AWS account, ensuring that sensitive prompt data and responses never leave your control.
- Built-in Infrastructure
Unlike platforms like LiteLLM that provide only code, Apiary includes pre-configured serverless infrastructure that can be deployed with minimal setup, offering the ease of setup typically found in managed services, without the data sharing concerns.
- Feature Set
Apiary includes advanced features that are often available only in premium tiers, or that require third-party integrations and configuration, when using existing offerings:
- Semantic caching, which compares the meaning of new requests to previous ones using vector embeddings
- Conversation thread management, for maintaining chat history across models
- Content guardrails, for detecting and managing undesirable responses
- Cost Efficiency
Apiary is free and open-source, requiring only the cost of the AWS infrastructure it runs on and the fees charged by LLM providers.
Who Apiary Is For
Apiary is built for small to medium-sized development teams working on AI-integrated applications where reliability, cost-efficiency, configurability, and observability are crucial. It provides a centralized point for managing aspects like API keys and guardrails, minimizing the coordination needed between different systems and team members. Built-in observability allows developers to monitor performance and track the life cycle of a request through the system. Features like conditional routing, fallbacks, and caching help to optimize application performance and costs. Each of these features is configurable, allowing developers to optimize Apiary for their specific applications' needs.
A Walkthrough of the Apiary Dashboard
Once deployed, Apiary provides users with two primary endpoints:
- A request endpoint where client applications can send prompts and receive responses from configured LLMs
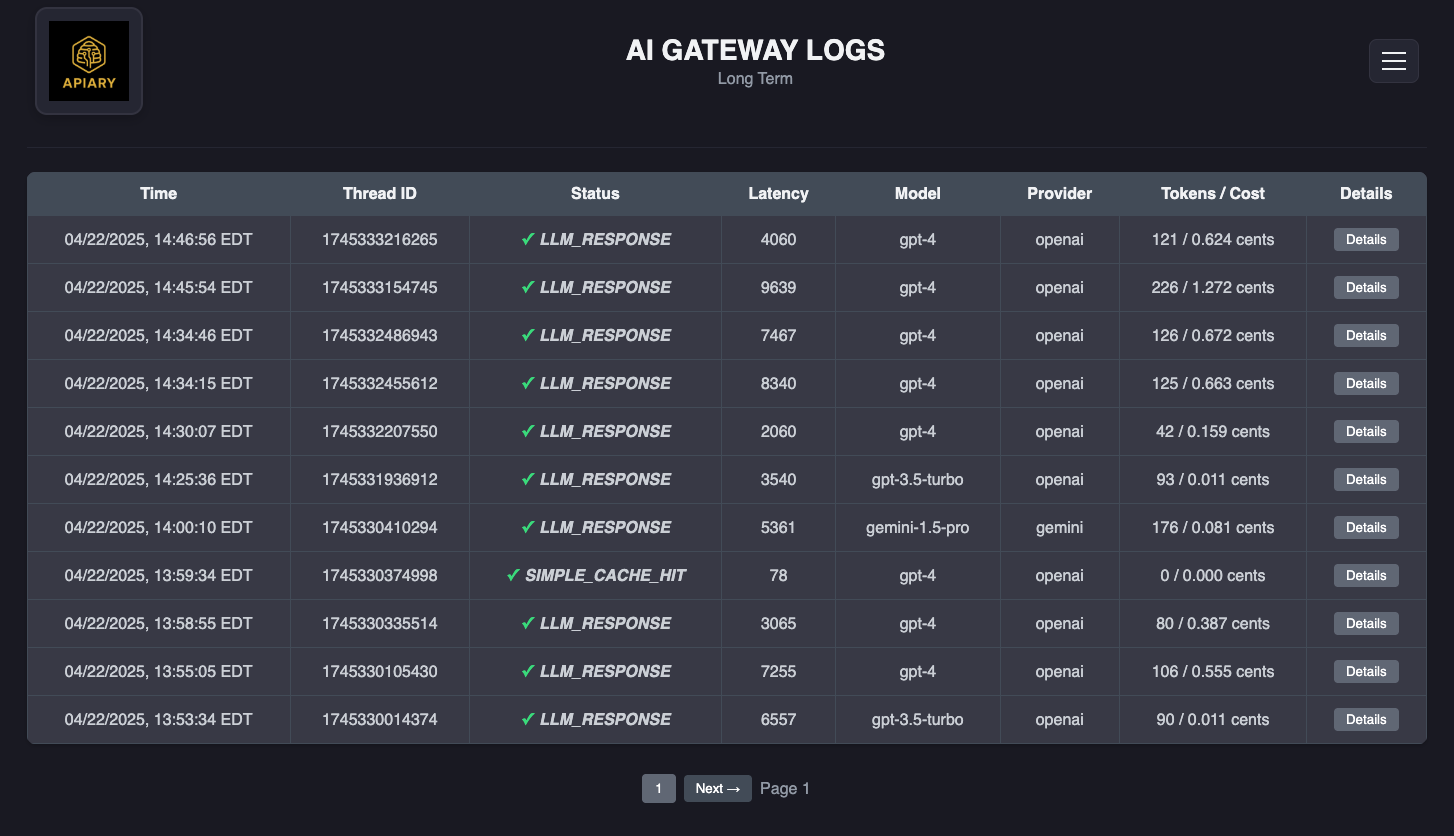
- An observability and management dashboard where users can view their request logs and configure routing, caching, fallback, and guardrail settings through a user interface
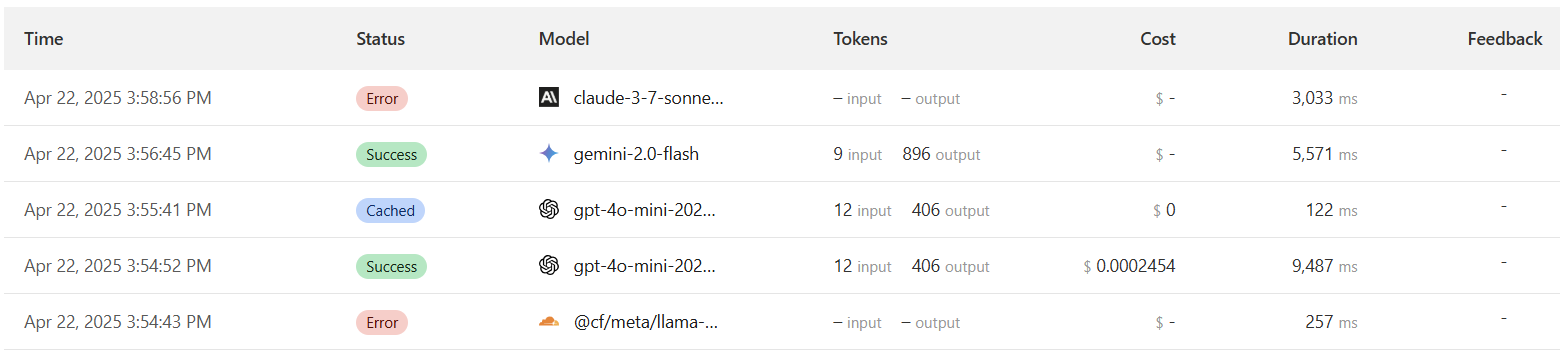
The Apiary user interface is designed to give developers full visibility of their LLM requests, as well as control over how the requests are routed. Here's a walkthrough of the key areas:
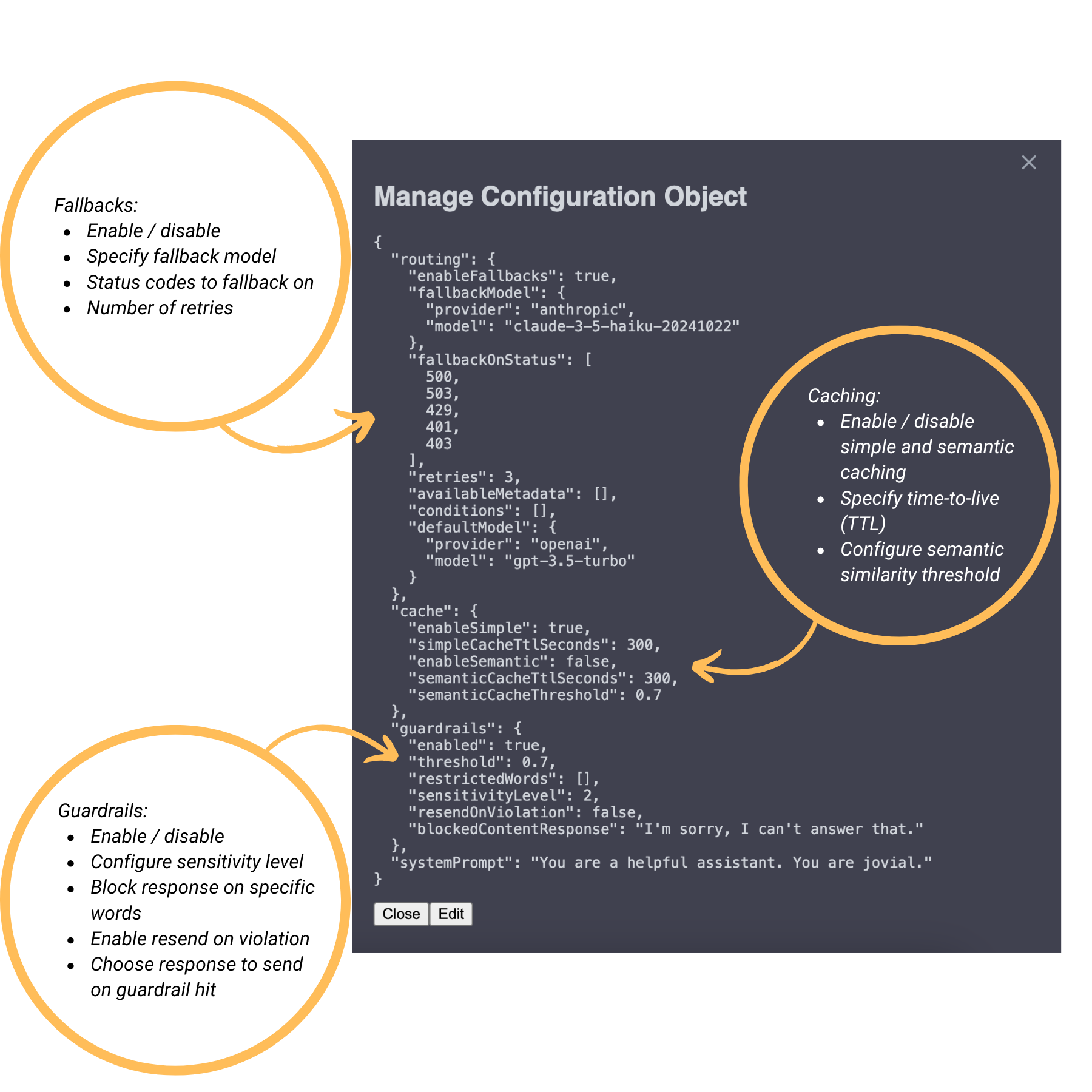
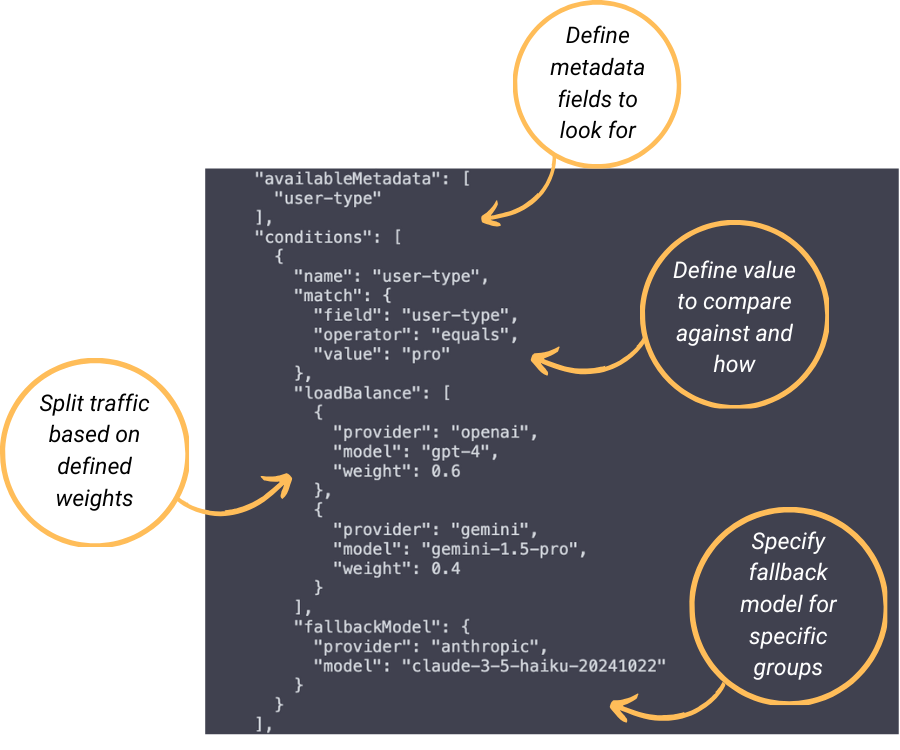
availableMetadata and conditions arrays.In the below configuration, Apiary will look for a request header of "x-user-type", and if the value in that header is "pro", the request will be routed to OpenAI's GPT-4 model 60% of the time, and Gemini's 1.5 Pro model 40% of the time.
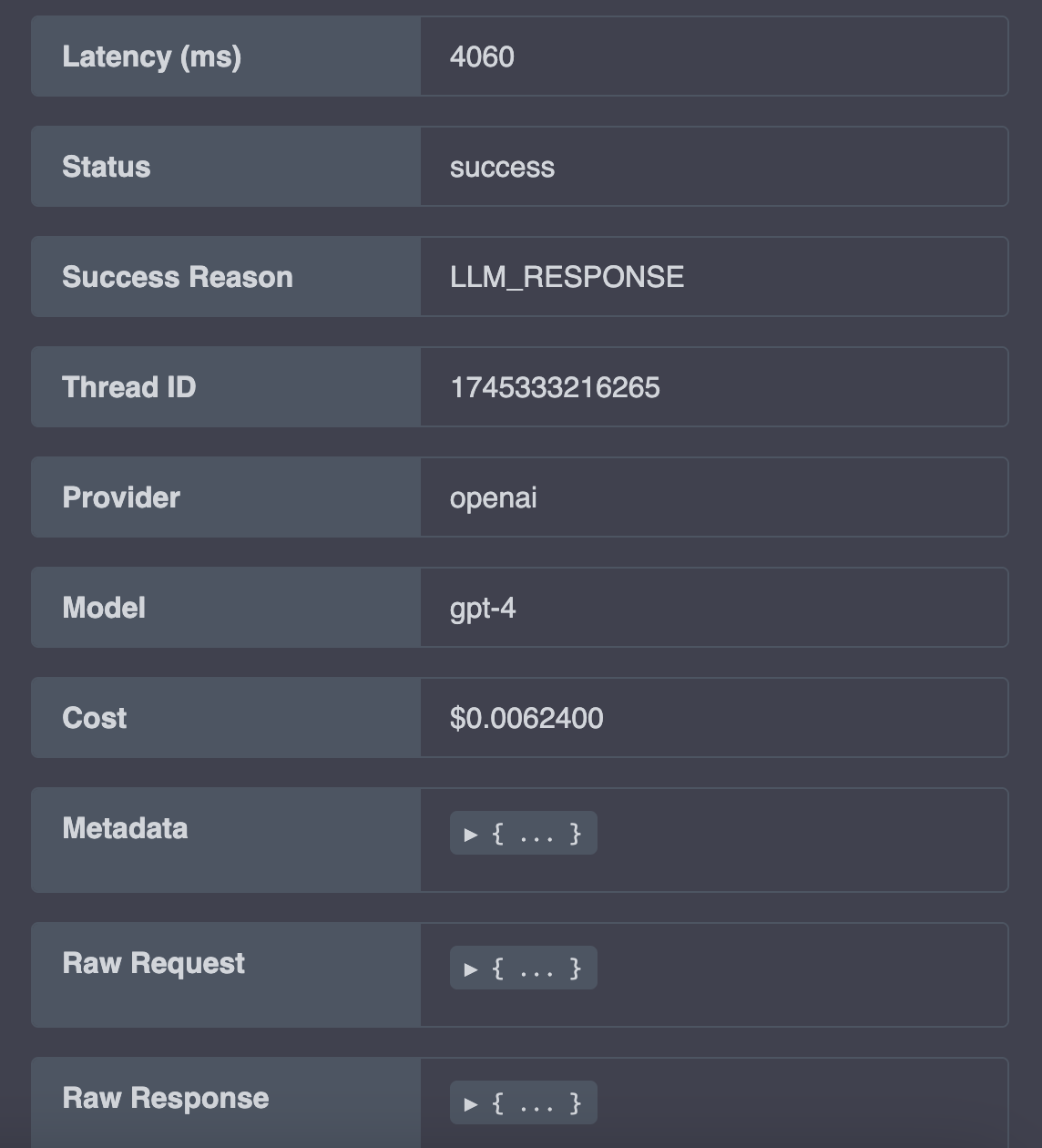
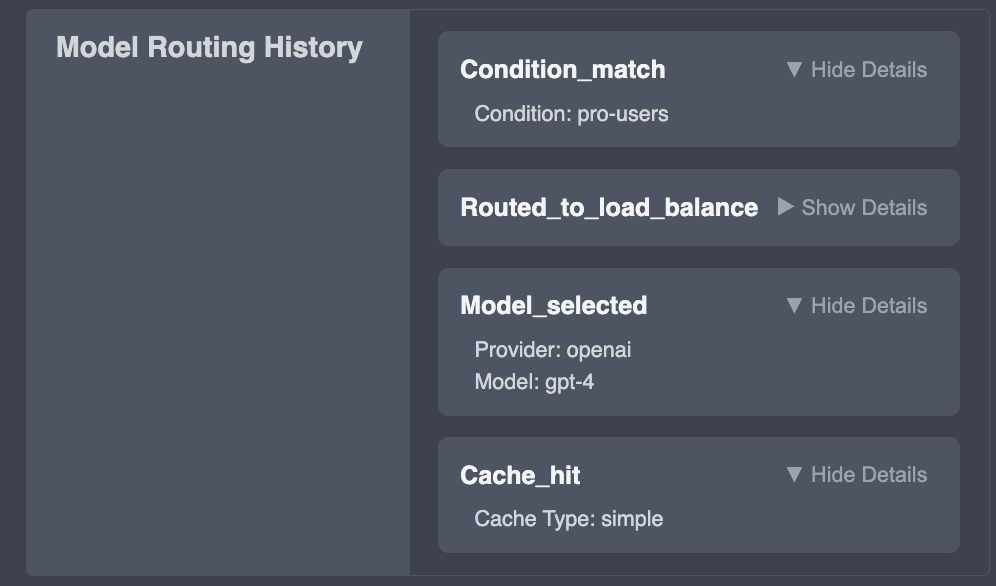
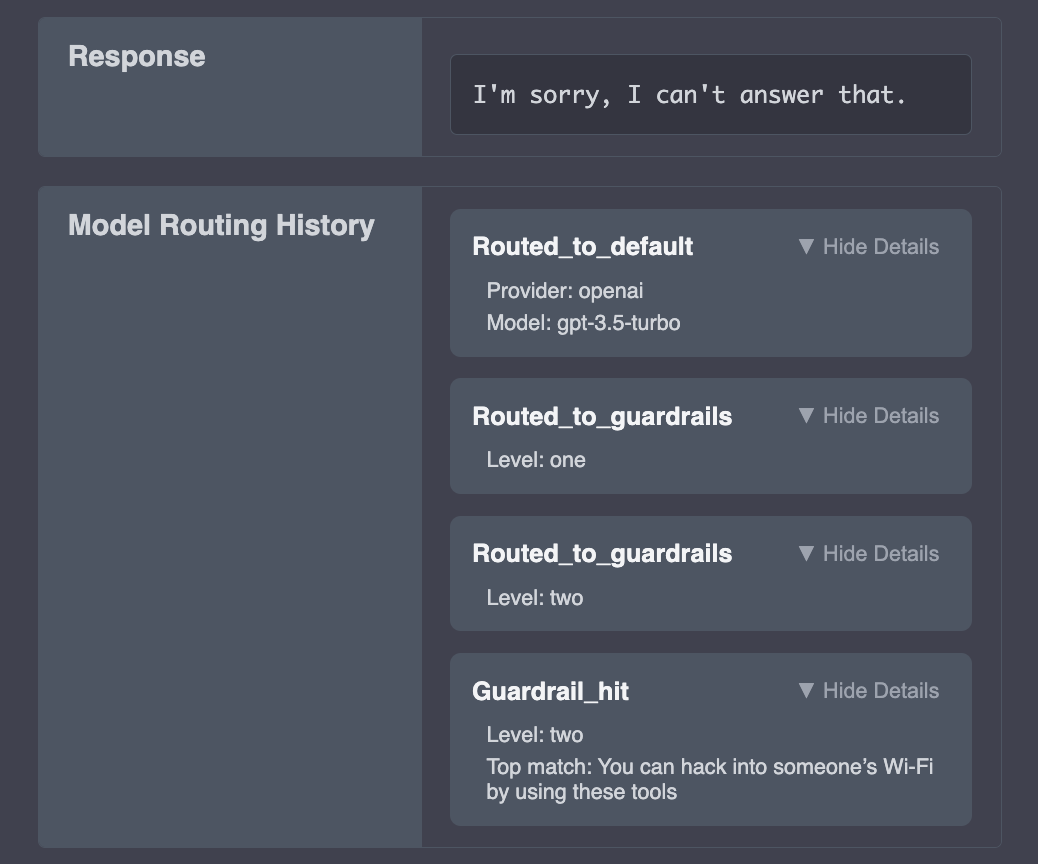
Life Cycle of a Request
The below diagram provides a visualization of the path of a request through Apiary:
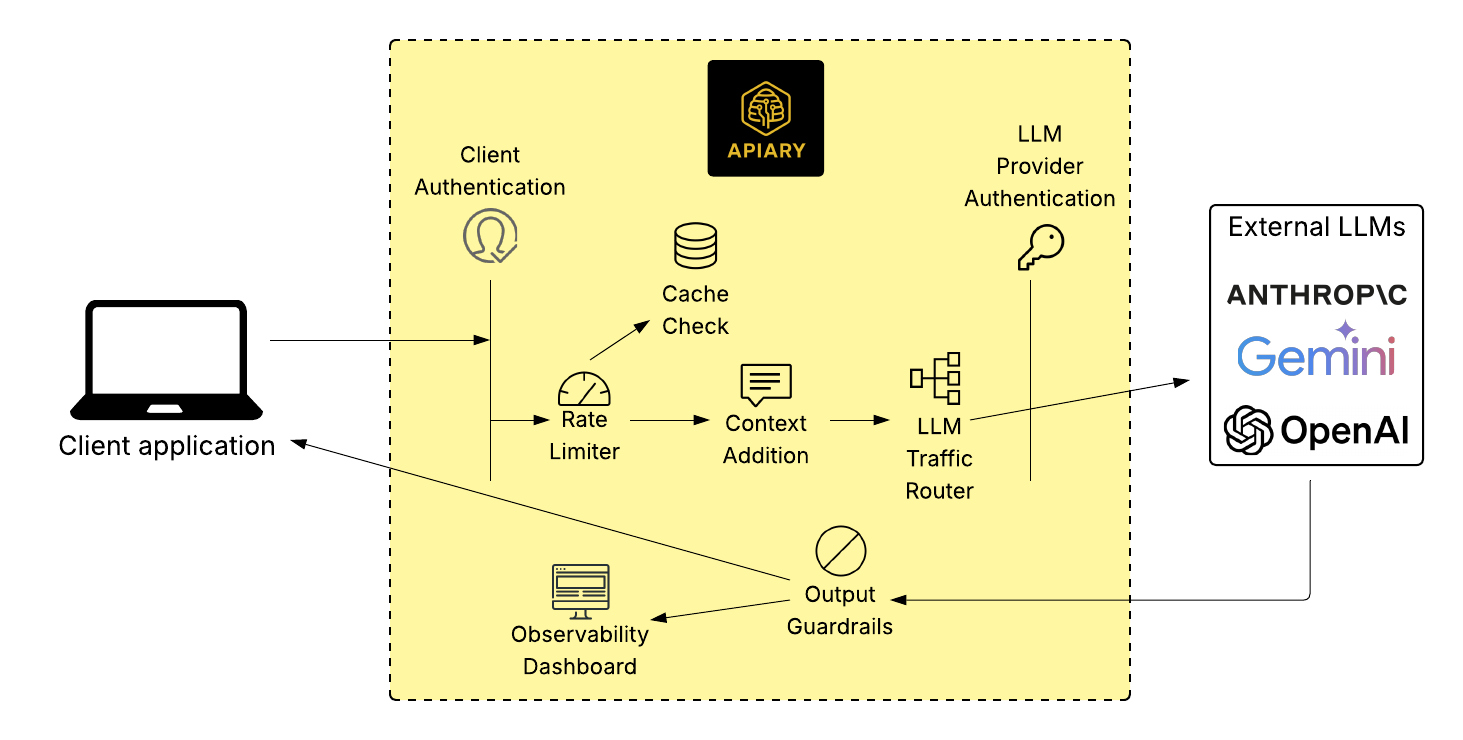
Getting Started with Apiary
Users can get started with our Command Line Interface (CLI) tool. The CLI tool provides commands to automatically deploy (and destroy) Apiary infrastructure using AWS Cloud Development Kit (CDK).
Once the user's infrastructure is deployed, they can navigate to the observability and management dashboard to configure their desired settings. Once configured, the Apiary Software Development Kit (SDK) can be used to send client requests to the system.
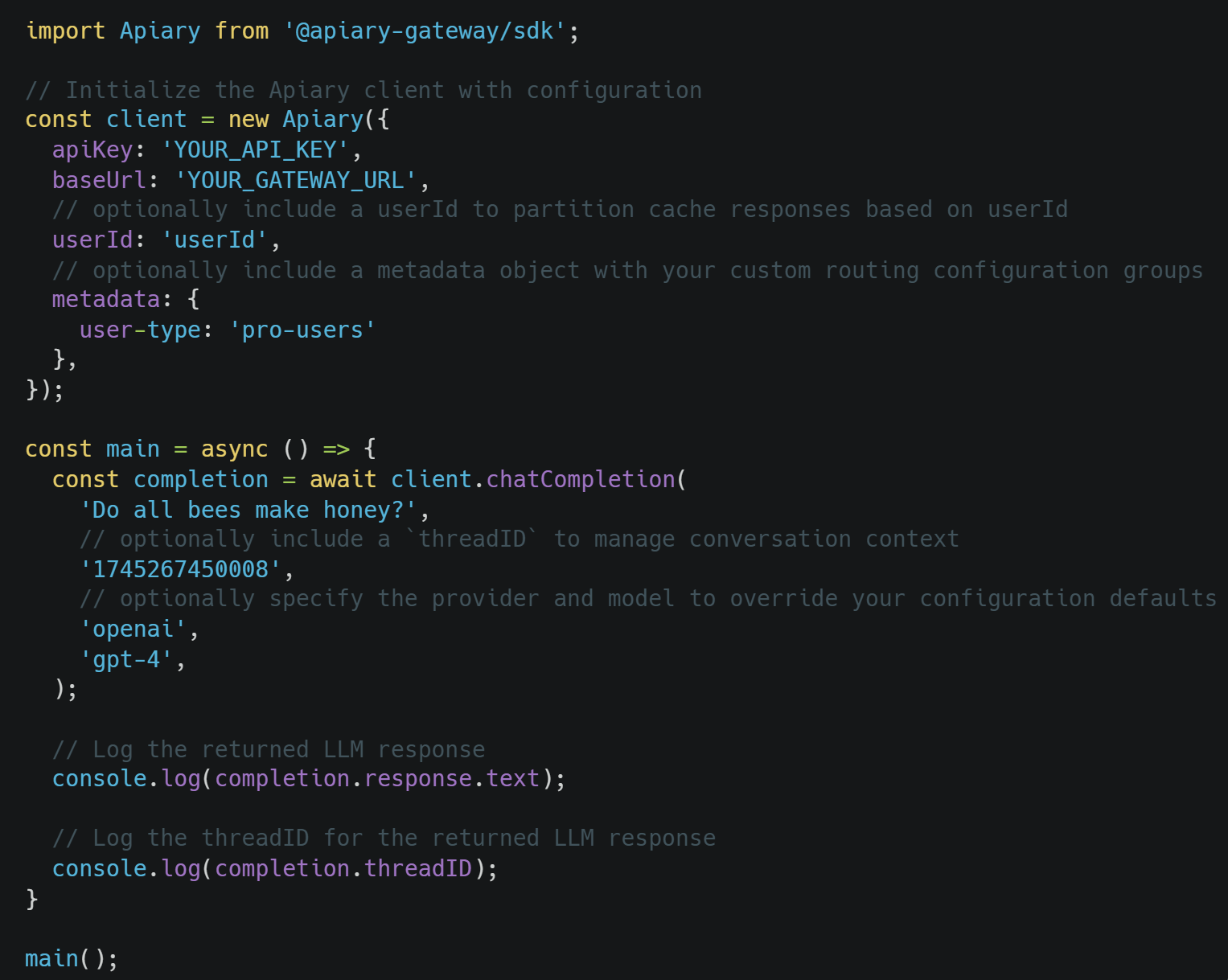
Building Apiary
Serverless Architecture
The Challenge
Our first major decision was selecting an initial architecture that would serve as a solid foundation for Apiary. We needed a solution that would present client applications with a simple, secure, and consistent interface - in the quickly evolving LLM landscape, the architecture should allow for updates on the backend without changes in how client applications interact with Apiary. The architecture needed to provide flexibility, enabling us to easily integrate features like authentication, dynamic routing, and observability. Additionally, we wanted a scalable solution that would accommodate applications with variable workflows.
Our Implementation Choices
We chose Amazon API Gateway paired with AWS Lambda as the foundational components for Apiary. API Gateway's built-in capabilities - such as acting as a "front door" for backend APIs and centralizing management of key functions like authentication and rate limiting - made it a natural choice.
Behind this gateway, AWS Lambda handles dynamic workloads by running functions that execute only when triggered by incoming requests. AWS Lambda's pay-per-use pricing model means we incur costs only for actual usage, making it efficient for periods of low traffic. Additionally, Lambda's automatic scaling ensures that our system can adapt to sudden spikes in demand without manual intervention.
For additional context, we'll provide a technical overview of API Gateways and their possible integration options before exploring the tradeoffs and considerations of our implementation.
Technical Overview
API Gateways act as centralized entry points for client applications to access backend services or APIs. They route incoming client requests to the appropriate backend services and handle common concerns such as authentication, rate limiting, and request/response transformation. Because clients interact only with the API Gateway, backend services can be updated or even replaced without requiring changes on the client side.
API Gateways can integrate with various backend architectures, including:
- Traditional servers (e.g., EC2): These offer complete control and flexibility, but require upfront provisioning, manual scaling to accommodate variable traffic, ongoing management, and fixed costs even during periods of low demand.
- Container-based solutions (e.g., ECS/EKS): Containers provide greater portability and scalability compared to traditional servers. However, they also introduce deployment complexity, management overhead, and typically higher baseline costs.
- Serverless computing (e.g., Lambda): In serverless computing models, cloud providers dynamically manage the allocation and provisioning of servers. This means that serverless architectures automatically scale based on demand and don't require upfront provisioning.
Tradeoffs and Considerations
AWS Lambda has inherent limitations, notably the "cold start" latency - a brief initial delay (around 200ms) encountered when invoking a Lambda function after a period of inactivity. However, after this initial invocation, subsequent requests benefit from a "warm" Lambda instance, significantly reducing latency. Another limitation is Lambda's maximum execution duration of 15 minutes per request. For our typical LLM interactions, which generally complete within seconds, this rarely poses any practical issues.
Ultimately, choosing a serverless foundation allowed us to prioritize our development efforts on Apiary's unique capabilities rather than infrastructure management, setting a flexible and efficient base for ongoing work.
Request/Response Transformation
The Challenge
As we've discussed, each LLM provider implements their API differently. The variations in parameter naming, request structure, and response formats must be handled in order to build a unified API. The transformation logic can become complex, but more importantly, as providers update their APIs, the logic in the model gateway must be updated as well.
For instance, to access the text response from OpenAI, you need to access the content property of the message object of the first element of the choices array in the response object. For Anthropic's Claude models, you need to access the text property in the first element of the content array in the response object. As another example, with OpenAI, if you want to include a developer prompt, you include the "developer" role in the input messages array sent in the request. To do the same with Claude, you must use the top-level system parameter — there is no "system" role for input messages in the Messages API. If you include a "system" role in your input messages, an error is thrown.
Our Implementation
After evaluating various approaches, we chose to wrap an established library. We built our core transformation logic around TokenJS, an open-source library that normalizes interactions with LLM providers.
Wrapping a library offered several advantages:
- Reduced maintenance burden - The wrapped library stays up-to-date with API changes from almost all of the prominent providers. Wrapping a library means that we're relying on the library maintainers to make any necessary changes rather than trying to keep track of each individual change ourselves.
- Immediate access to many providers - The library already supports a wide range of LLM providers.
- Faster development - We could focus on higher-level features rather than low-level API integration.
In our initial benchmarking, we found that wrapping the library added some latency. For example, a simple call to Claude 3.5 Sonnet took ~2500ms via the wrapper, compared to ~1250ms with a direct call. However, this was acceptable to us given that the typical latency range for LLM calls are 5000ms or more 4. This tradeoff was worth it to us for the improvement in maintainability and development speed.
Alternative Approaches and Tradeoffs
In making our decision to use TokenJS, we considered two alternatives: using the built-in request/response mapping templates in AWS's API Gateway, and building a custom transformation layer from scratch. We found the API Gateway transformations to be slightly restrictive and difficult to configure, so we quickly moved on to consider creating our own transformation layer. While we were initially drawn to this option for the control and flexibility, we realized that in such a quickly changing space, we should take advantage of a library that handles any updates for us. The other side of this coin is that our decision creates a dependency risk - should the TokenJS library maintainers fall behind on updates or abandon the project, our model gateway would also fall behind. Ultimately, we felt the reduction in development effort and maintenance overhead was worth some risk that the TokenJS library becomes outdated.
API Key Management
The Challenge
Working with multiple LLM providers requires managing separate API keys for each provider. This presents several challenges for development teams, particularly for teams where multiple developers need access to these credentials.
Keys must be securely stored to prevent unauthorized access. Any compromise of these keys could lead to unauthorized usage, costs, and potential data exposure. Key rotation should be possible without service disruption. Additionally, any key management solution should be able to accommodate adding (or removing) LLM providers and securely sharing access with new team members.
Our Implementation
For Apiary, we implemented a two-tier key management strategy that balances security with usability.
Our provider API key management system uses AWS Secrets Manager to securely store all LLM provider API keys. Lambda functions retrieve the necessary keys when processing requests, ensuring that keys are not exposed to client applications and reducing the risk of key leakage.
Requests from client applications to Apiary are authenticated with a single API key issued by Apiary. Different usage plans associated with different API keys, and with varying rate limits, can be created for different clients. This approach simplifies key management for client application developers - they only need to manage a single API key, regardless of how many LLM providers are used behind the scenes. LLM providers can be added without sharing provider keys with individual developers - developers can simply use their Apiary API key. LLM provider keys can be automatically rotated in Secrets Manager, ensuring continuous application operation.
This approach maintains security for provider credentials while providing a simple, unified authentication mechanism for client applications.
Alternative Approaches and Tradeoffs
It's not uncommon for teams to store API keys in a .env file, but we didn't consider this approach due to security risks and impracticality for production environments or team-based workflows. Another alternative was using an external tool like HashiCorp Vault, but that would introduce operational complexity and management overhead we didn't need. Given that we were already in the AWS ecosystem, Secrets Manager was a natural fit.
Managing Conversation History
The Challenge
Many LLM applications require maintaining the context of ongoing conversations, or threads, which presents several challenges, the most fundamental being that each LLM request is stateless by default. When conversation history is required for context, the entire history must be provided with each request. This requires that we not only store and access the conversation history for each request, but also transform it either before storage or upon retrieval to ensure that different providers can parse it. Given that we had already addressed the issue of varying request and response structures and roles with the TokenJS library, this challenge was simplified in that respect.
A complication worth mentioning is that as the conversation grows, the requests to the LLMs grow in size as well, increasing the token count and associated cost. Long conversations may also lead to a loss of context, as there is an upper limit to the amount of context an LLM can support.
Managing threads effectively requires persistent storage, standardization across providers, and strategies for handling long-running conversations.
Our Implementation Choices
When a user sends a prompt to Apiary, they can either provide a threadID or let the system automatically generate one using a UUID. This threadID acts as a key for the conversation, allowing us to link each message in a thread together.
Every query and its corresponding response is stored in a DynamoDB table. Standardization via our wrapped library ensures the conversation has been normalized prior to being saved. When a new message arrives with a threadID, Apiary retrieves the full message history associated with that thread. This history is then passed along with the new prompt to the LLM, giving it the full conversational context.
This implementation provides thread management without requiring clients to manage conversation history themselves. The conversation context is automatically maintained and provided to each new request in the thread.
Alternative Approaches and Tradeoffs
In formulating our implementation of thread management, we considered a couple of other approaches. While exploring other model gateways, we found that Portkey has separate APIs for thread and chat completion. As users, this felt clunky and complicated to us, so we decided a single API for a chat completion, whether it's part of an ongoing conversation or not, was a better approach.
Another approach would have been to use each provider's thread API, where available. While this might seem like a logical fit, it would have introduced major complications. For one, not all providers offer this feature, so we would have been limited in which providers we could support. Secondly, if a conversation started with one provider, we would need to retrieve the thread history from their system and reformat it before routing the next message to another provider. This would have complicated one of our main functionalities - multi-provider routing. By managing the thread history ourselves in a normalized format, we retained control of the storage and retrieval of the conversation history and simplified cross-provider functionality.
In considering how to handle the effects of a thread that has grown too long, we explored several options. We could have implemented a configurable limit on thread history, either based on the number of exchanges or token count. We also discussed potential responses when that limit is reached - perhaps leveraging an LLM to summarize previous conversation content, or simply returning an error code and requiring users to start a new conversation. Ultimately, given the complexity and variety of potential use cases, we decided to delegate this responsibility to Apiary users, allowing them to implement thread management strategies that best suit their specific needs. This remains an area we're interested in developing further in future work.
Configurable Routing
The Challenge
As we've discussed, routing requests to the appropriate LLM based on an application's specific needs is one of the paramount features of a model gateway. Thoughtful routing configuration will reduce downtime, minimize costs, create an ideal setup for development and testing, and produce better responses.
The primary challenge in implementing a configurable routing system stemmed from our desire for exceptional flexibility. The core difficulty lay in designing a system that could elegantly handle a multi-layered decision tree. Our routing system needed to support:
- Request-level provider and model specification
- Configuration-level defaults
- Conditional routing based on request metadata
- Traffic distribution within condition groups (load balancing)
- Multiple layers of fallback mechanisms
The challenge wasn't simply implementing each feature in isolation, but determining the ideal flow of a request and then creating a cohesive system where these options could interact predictably. When a request enters the gateway, it triggers a cascade of routing decisions, each with its own set of rules and fallback behaviors.
Technical Overview
Potential use cases of conditional routing might be to route queries with a user-type header of pro, for example, to better, more expensive models, or queries with a department header of legal to specialized models trained on contracts.
Fallback Mechanisms are essential, as LLM services experience higher-than-typical downtime. Number of retries and status codes to fallback on are also configurable through Apiary.
Load Balancing supports experimental needs, setting users up for canary deployments and A/B testing with no additional configuration.
Our Implementation
It was important to us that, in choosing to use Apiary, developers did not have to sacrifice control over request routing. We implemented a routing system with the goal of providing as much flexibility as possible.
Configuration Object: Routing rules are defined in JSON and stored in an S3 bucket. Our default configuration file is loaded upon deployment, with the option for users to update the configuration through the UI.
Fallback Mechanisms: The system handles transient failures through configurable automatic retries with exponential backoff. Users can specify fallback models at multiple levels (per condition and globally) and define which error status codes should trigger these fallbacks.
Load Balancing: Our implementation supports percentage-based distribution across providers, enabling controlled rollouts through A/B testing and canary deployments.
Granular Control: The system processes routing metadata from request headers. This creates a pathway for specialized routing needs, such as directing specific user segments to appropriate models.
This implementation allows for sophisticated routing strategies while maintaining a simple API for clients. The routing layer handles the complexity of provider selection, retries, and fallbacks, making these concerns transparent to the application making the request.
Alternative Approaches and Tradeoffs
When designing the routing system, we considered a couple of other options. We could have implemented a more basic approach with predetermined paths. This approach would have certainly been easier to build, but as users of model gateways ourselves, we had experienced the frustration of limited options and knew we wanted complete flexibility. Another option was to use the pre-built routing features of Amazon's API Gateway. This could have saved development time, but would have limited us with respect to implementation. We knew we would require specialized fallback logic, context-aware routing, and eventually in future developments, streaming response management, which API Gateway would not be best suited for.
Caching
The Challenge
As discussed, common developer concerns when working with LLMs include cost and high latency, especially compared to traditional API calls. Response times can vary significantly depending on the model, the length of the input prompt and generated output (measured in tokens), and the current load on the provider's infrastructure 5. Tracked response times increase when using more powerful models4, and may increase even further when requesting longer outputs.
LLM pricing also varies based on the provider and model, but is generally charged based on tokens used. As of this writing, OpenAI's GPT-4.1 model - which it touts as a "model for everyday tasks" - costs $2.00 per million input tokens and $8.00 per million output tokens. o1-pro, one of OpenAI's most advanced models, costs $150.00 per million input tokens and $600.00 per million output tokens. Costs can add up even when using a cheaper model, especially for high traffic applications.
Our Implementation
To help mitigate the latency and costs of LLM calls, Apiary implements both simple and semantic caching. Users have the option to enable one, both, or neither of these caches, depending on their needs.
Before diving into our implementation details, we’ll provide a technical overview of simple and semantic caching systems to ground the discussion.
Technical Overview
In a caching system, responses to prior requests can be reused, rather than calling the LLM again. In simple caching, a cached response is only returned if the request matches the previous one exactly. For example, the queries "How do bees make honey?" and "How do bees produce honey?" wouldn't be recognized by a simple cache as equivalent requests, even though it might be reasonable to return the same response in this case.
Despite the variability of language and relatively low likelihood of identical phrasing between requests, LLM-integrated applications can benefit greatly from a simple cache. For instance, applications with suggested pre-defined prompts, where the exact same prompt might be sent repeatedly, would result in a high number of simple cache hits. A simple cache can be particularly valuable during development, when a cached response may be preferred to avoid the token usage and latency of an LLM call.
In contrast, semantic caches are able to recognize the meaning of requests - so that queries like "How do bees make honey?" and "How do bees produce honey?" are identified as semantically equivalent and result in a cache hit.
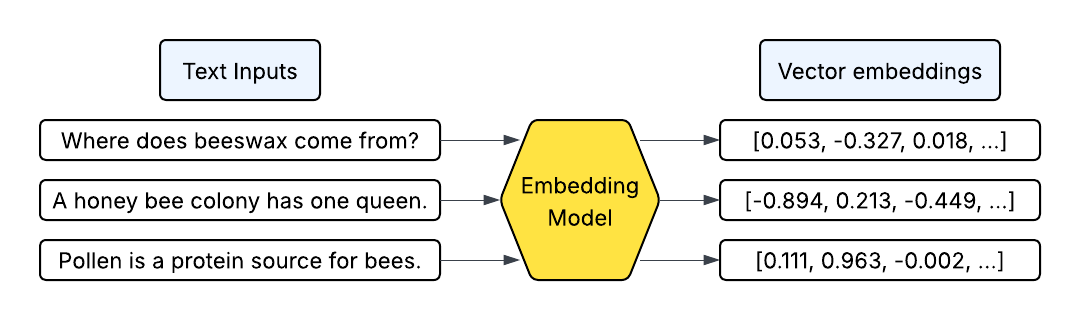
Semantic caching uses vector embeddings, which are arrays of hundreds or thousands of numbers that represent the characteristics of a piece of data, like a sentence or a paragraph. Embedding models have been trained to convert inputs like sentences into vector embedding outputs representing the inputs' features. Embeddings can be compared using cosine similarity, a calculation that measures how similar two embeddings are to each other. The higher the cosine similarity, the more similar the embeddings. Vector embeddings can be stored in a category of databases called vector databases, which are optimized for storing and searching high-dimensional vector embeddings.
Simple cache
If both simple and semantic caches are enabled, Apiary checks the simple cache first. Due to its simpler nature, the simple cache is able to return a response faster than the semantic cache.
Apiary's simple cache uses DynamoDB, which we chose for its simplicity, single-digit millisecond response times, and easy integration with other AWS services. Requests can be cached globally or per user by including a userId in the request. Each entry's "sort key" is created by combining the LLM provider and model used, with the text of the user request. This accommodates cases where developers want a response to be provided by a specific provider and model due to that model's strengths in some area.
Cache items are automatically deleted using DynamoDB's built-in time-to-live (TTL) functionality. Developers can specify a TTL in seconds that works best for them.
Semantic cache
If no match is found in the simple cache, Apiary checks the semantic cache (if enabled) next. The semantic caching system follows this process:
- A vector embedding for the request is generated.
- The embedding is compared against previously cached embeddings using cosine similarity.
- If a match is found in the cache with a cosine similarity above a configurable threshold, then the cached response will be immediately returned to the user.
- If no match is found above the threshold, then the request will be sent to an LLM.
- When the LLM responds, its response will be stored with the embedding for the request in the vector database.
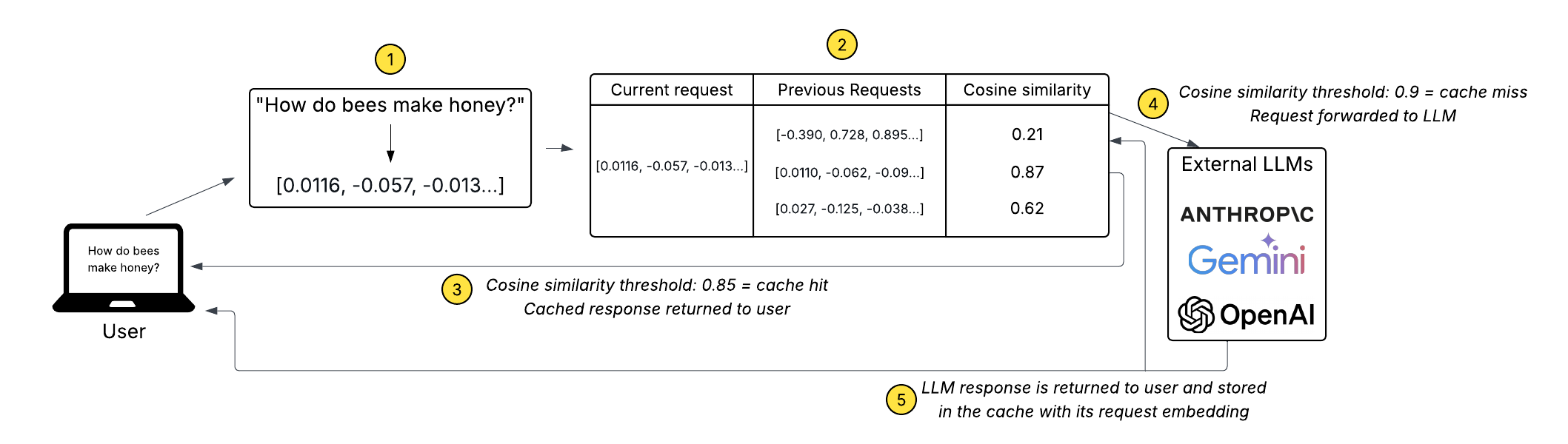
Apiary's semantic caching system uses the Amazon Titan Text Embedding v2 model via AWS Bedrock to generate embeddings. Bedrock is fully managed and easy to integrate with other AWS services, making it a convenient choice for our infrastructure. For storing and searching embeddings, Apiary uses AWS OpenSearch vector search. OpenSearch vector search is a vector database and search tool that is also well-suited for searches that filter on metadata. This allows us to filter semantic cache hits based on userId, provider, and model, just as we do in the simple cache. The semantic cache also implements configurable TTL for cache entries.
Alternative Approaches and Tradeoffs
Simple Cache
Before choosing DynamoDB for our simple cache, we considered using the built-in API Gateway caching. This approach would require no additional components, but we quickly found that the functionality of this system was too limited for our needs. Making requests to LLMs requires complex prompts that are better suited for sending in the body of HTTP POST requests. The built-in API Gateway caching doesn't allow for accessing the request body. Additionally, it returns the full cached response, including fields like token usage that aren't sensical to return with a cache hit. Implementing a custom cache solution allowed us to customize the response appropriately.
Semantic Cache
For embedding generation, we considered making API calls to connect to external models (ex. from OpenAI or Anthropic), which would give us access to more options, but this would require an external network connection outside of the AWS ecosystem. We also considered running a local embedding model to avoid the external call, but this would add considerable complexity to our system.
For both the simple and semantic caching systems, we also considered using in-memory caches like ElastiCache or MemoryDB with vector search. While these would have faster response times (sub-millisecond for a simple cache with ElastiCache, and estimated in the low tens of milliseconds for MemoryDB with vector search - vs mid to high tens of milliseconds for OpenSearch), they would also introduce additional complexity and cost to the system. Since OpenSearch is already used elsewhere in Apiary (e.g., for guardrails), it made sense to standardize on one tool. LLM users are also accustomed to some delay, so the slightly higher latency of OpenSearch was acceptable for our use case.
Guardrails
The Challenge
One difficulty when working with LLMs is that their behavior is non-deterministic. Their responses can sometimes generate inappropriate, inaccurate, or potentially harmful content. To implement some protection against undesired behavior, developers may wish to apply some variation of guardrails at one or more steps in the request and response flow. Determining where guardrails should go and how they should be implemented presented a design challenge in our pursuit to balance the linguistic strengths of an LLM with safety and consistency. To provide some context, we'll provide a technical overview of guardrails before diving into our implementation decisions.
Technical Overview
Guardrails can be implemented at various "intervention levels" in an LLM application, including on the user's query, on any retrieved supplemental information (such as in a RAG), on the LLM's response, and on what is finally returned to the client. At each level, guardrails can determine whether messages should be accepted as is, filtered, modified, or rejected.
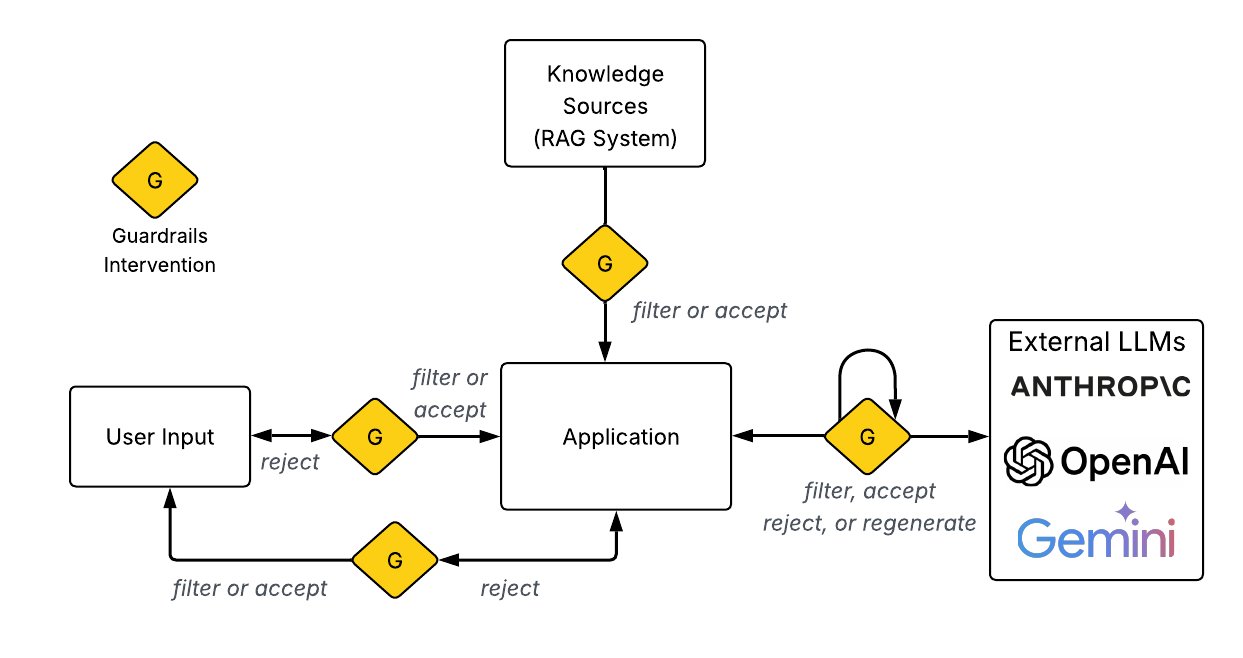
The main techniques for implementing guardrails include:
- Rule-based string manipulation: These guardrails take a string as input, perform checks or string modifications, and determine the next steps. While this approach is typically fast and low-cost, language can be subtle and context-dependent, so rule-based approaches are the least robust.
- LLM-based metrics: These use embedding similarity metrics to estimate how similar a message is to target topics. For example, calculating the semantic similarity between user input and problematic content. This requires embedding a group of "utterances," storing them, and chunking and embedding each LLM response to analyze the semantic similarity between the response and the utterances. This approach is more restrictive, but also increases latency and cost.
- LLM judges: These guardrails use LLMs themselves to evaluate whether content violates guidelines. While powerful, this adds significant latency and cost to each interaction.
- Prompt engineering: This uses carefully designed prompts to steer the LLM away from generating problematic content. When done well, prompt engineering can be very effective, but its effectiveness is largely dependent on an LLM's capacity to accurately interpret instructions. Applications using prompt engineering alone are also susceptible to prompt injection attacks.
In designing guardrails, developers must balance several competing factors as they fit their specific needs: maximizing the capabilities of LLMs, ensuring safety and relevance of responses, minimizing latency, and managing costs.
Our Implementation
As we've discussed, there are a number of factors that need to be tailored for each situation's needs. For this reason, we chose to make our guardrails system highly configurable. We designed Apiary to offer a number of options:
Level One Guardrails: Rule-Based String Manipulation
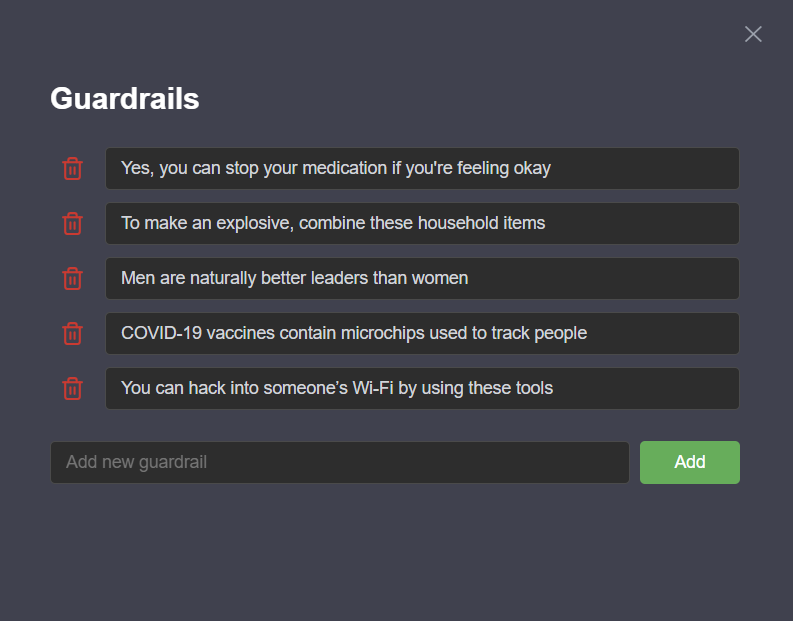
Our first tier implements simple rule-based guardrails that match LLM outputs against an array of blocked words included in the configuration object. This approach:
- Provides a latency impact of about 300ms
- Catches obvious violations (explicit profanity, prohibited topics)
- Can be easily customized with domain-specific blocklists
This approach acts as a basic layer of defense, with minimal added latency and no added cost.
Level Two Guardrails: Semantic Similarity Matching
Our second tier implements more sophisticated guardrails using semantic similarity:
- Uses embeddings to detect semantic similarity to prohibited content
- Can catch subtle violations that would bypass word-based filtering
- Leverages our existing OpenSearch infrastructure for embedding storage and similarity calculations
- Provides more comprehensive protection at the cost of moderately increased latency (1000ms)
This technique computes semantic similarity scores between 3-sentence chunks of inputs/outputs and target problematic content, rejecting the message whenever the score exceeds a specified, configurable threshold.
Resend On Violation
For cases where guardrails detect violations, we implemented a "resend on violation" option that:
- Sends responses that trigger guardrails back to the LLM
- Includes instructions to generate a new response that avoids the detected violation
- Incorporates the "LLM judge" technique without adding latency to every request
- Provides a fallback mechanism when guardrails block legitimate content
As this approach requires an additional LLM call, it adds the highest amount of latency (approximately 2000ms) and cost, but it results in a much more comprehensive safety framework while still returning a useful response. Rather than simply blocking content, it adaptively regenerates responses while avoiding violations.
No Guardrails
Lastly, our guardrails are completely optional. For users who would prefer to do without any sort of guardrails, the enabled attribute in the guardrails section may be set to false in the configuration object.
Alternative Approaches and Tradeoffs
For the level two guardrails, our current implementation includes prompt and response content together during evaluation. While this approach maintained the context of the question (for instance, an LLM might not restate the topic at hand and simply respond with an undesired affirmation or rejection, which wouldn't be caught), it created a new challenge: if a prompt mentions prohibited content, the entire response might be blocked unnecessarily. The core challenge is striking a balance between:
- Not blocking valid responses that refute misinformation or discuss sensitive topics in an acceptable way
- Catching harmful outputs, even if they're short ("yes") or rely heavily on context from the prompt
We considered a few improvements to this system as opportunities for future refinement:
- Determine stance of the response (affirms or rejects), and only block those responses that affirm the prohibited utterances.
- Add metadata to guardrails such as "block_if_affirms," "block_if_prompt_includes," or "block_if_refutes" to introduce more granular control over enforcement.
- Apply different semantic similarity thresholds for prompts versus responses, with a higher threshold for prompts, or with a heavier weighting to response similarity in decision-making.
Ultimately, we found our current guardrails system to be a good balance of safety and simplicity. With full configurability, we felt that users of Apiary could fine-tune its behavior to suit their needs.
Collecting and Storing Observability Data
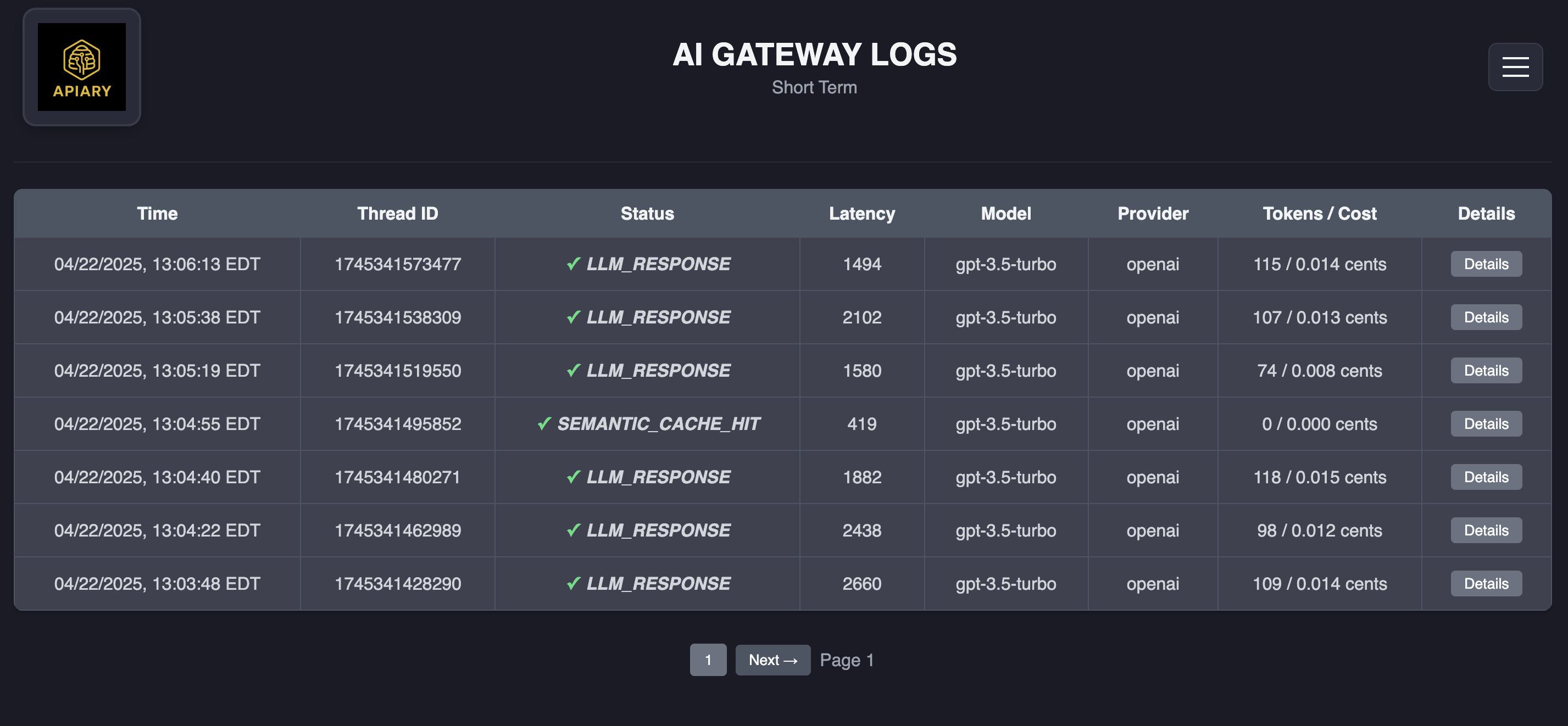
Short-term data
The Challenge
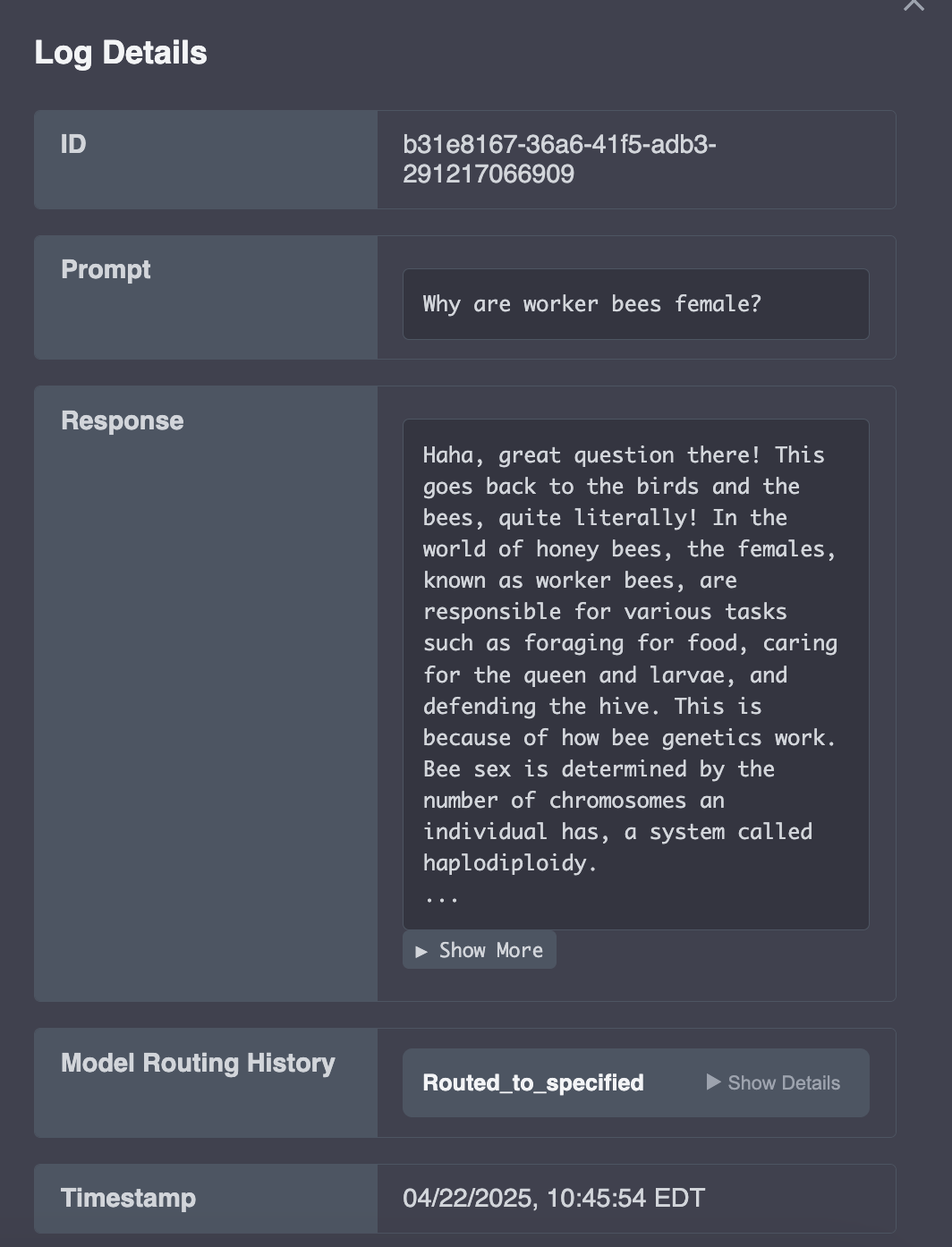
Apiary collects data on every request passing through the system, categorizing this information into short-term and long-term logs. Short-term logs represent requests from the past 5 days. Developers require near real-time access to these logs to quickly monitor system performance and detect anomalies or errors.
Our Implementation
We chose to use AWS DynamoDB for short-term log storage. Log data naturally aligns with DynamoDB's key-value structure, allowing each request's log to be stored as a single object. Additionally, DynamoDB's single-millisecond query latency ensures developers can retrieve logs almost instantly, meeting the need for near real-time observability.
Alternative Approaches and Tradeoffs
We briefly considered using a relational database for storing short-term logs. However, relational databases introduced unnecessary complexity because our log data is self-contained within individual records. The absence of complex relational joins makes a key-value store like DynamoDB a more straightforward and efficient solution.
Long-term data
The Challenge
Long-term log storage presents distinct challenges, particularly around efficiently storing and querying large volumes of historical data. Unlike short-term logs, the priority shifts toward facilitating aggregate queries (e.g., calculating averages or grouping data by provider) rather than rapid individual record retrieval. Therefore, our primary considerations here were query efficiency and cost-effective storage.
Our Implementation
Apiary stores its long-term log data as Apache Parquet files within Amazon S3, leveraging Athena to execute queries. This approach optimizes both storage costs and query performance due to Parquet's compression and the columnar design. Athena provides the option to run optimized aggregate queries on the data through familiar SQL statements.
Technical Overview
Apache Parquet is a columnar storage format that stores data by columns rather than rows, offering significant compression advantages. Columnar compression reduces the required storage space and significantly accelerates analytical queries since irrelevant columns can be skipped during queries 6.
AWS Athena, a serverless query service, enables querying data stored in Amazon S3 using standard SQL. When paired with parquet format, Athena efficiently reads only the required columns. Additionally, parquet files in S3 can be partitioned by specific columns, further optimizing queries by ensuring only necessary partitions are scanned. Bulk parquet data can be split into separate files, and Athena can run queries in parallel on those files.
Alternative Approaches and Tradeoffs
An alternative that we considered was storing logs in JSON format. JSON's advantages include human readability, easy interoperability with multiple platforms and tools, and suitability for row-based querying (ideal for accessing detailed individual request data). However, JSON lacks Parquet's storage efficiency and optimized query capabilities for large-scale analytics. Given our priorities of aggregate analysis and the potential scale of log storage, Parquet's compression and aggregate query advantages were decisive factors in choosing it over JSON.
Additional Considerations
Short-term logs are periodically transferred from DynamoDB to S3 via a scheduled cron job. This transaction is not atomic - that is, if any part of the function fails then the database does not revert back to its original state. Making this process more ACID compliant is an important area for future work.
Additionally, the logging and routing systems are currently tightly coupled. Routing functions directly instantiate or pass logging objects to capture events (e.g., cache hits). While this provides fine-grained event tracking with minimal overhead, it may become a bottleneck under sustained high traffic (e.g., over 100 requests per second). To improve scalability and performance, we could adopt an event-driven architecture where logs are asynchronously published to a streaming service such as AWS Kinesis Data Streams or Firehose, decoupling logging from routing.
Observability and Management Dashboard
Apiary includes an observability dashboard which allows developers to toggle between viewing short-term and long-term logs. The dashboard fetches logs from DynamoDB (for short-term logs) or Athena query (for long-term logs). The UI is implemented in React, stored in S3, and delivered via AWS CloudFront.
The dashboard also serves as a management hub where users can configure routing logic and guardrails. We considered different options for where to implement this "management hub" - for example by having users pass a configuration object in the SDK, or via CLI commands. Ultimately we felt that the dashboard UI was the most user-friendly option, where we could provide the most intuitive editing interface along with guidance on entering a valid configuration object.
Future Work
Apiary provides powerful capabilities for developing and managing LLM applications, but there are several areas where we can enhance the platform further. Our team has identified the following areas for improvement:
Improving Resiliency
- Streamline the complexity of migrating older logs from DynamoDB to Athena to make it ACID compliant. The current process involves many steps, and ideally we’d like to configure the process so that if one step fails, the process halts and rolls back all prior steps to their previous states before trying again.
- Decouple the routing and logging functionalities
User Querying
- Give users the ability to run their own custom queries on the observability data
Optimizing Latency
- Add in-memory caches to improve response times. While we made a tradeoff for simplicity over speed with our current caching systems, having an option to use faster in-memory caches might be worth it for certain use cases.
- Implement real-time streaming to improve the perception of latency
Conversation Management
- Implement prompt management systems for better control and organization
- Deploy token-based rate limiting to set limits on conversation history
- When conversation limits are reached:
- Leverage an LLM to summarize previous conversation content
- Or simply return an error code and require users to start a new conversation
Additional Guardrail Features
- Introduce more granular control over guardrails:
- Categorize the stance of responses (affirm or reject) and only block those that affirm prohibited utterances
- Add metadata to guardrails to allow for specific actions for each guardrail
- Apply different semantic similarity thresholds for prompts versus responses to more heavily weight the response similarity
By addressing these areas, Apiary can evolve into an even more robust, responsive, and effective platform for managing LLM applications.
References
This section contains all references cited throughout the case study.